NovelAIの画像生成の使い方(各パラメータの意味)を説明します。
次の2つで説明します。
- テキストのみで生成する
- 参考画像をインプットして生成する
両方で設定するパラメータについては「テキストのみで生成する」で説明します。
テキストのみで生成する
パラメータを上から順に説明します。
NovelAI Diffusion
Anime (Full)、Anime (Curated)、Furry (Beta)のいずれかを選択します。
そのままGoogle翻訳の説明を載せます。
| パラメータ | 説明 |
|---|---|
| Anime (Full) | 幅広いジャンルに対応 |
| Anime (Curated) | 優れたベースライン品質と予測可能な主題 |
| Furry (Beta) | 毛皮や擬人化された動物が主題 |
Furry (Beta)はベータ版で、これから拡張予定とのこと。
基本的にはFullでOKです。
ちょっとHな路線にしたいときはCuratedです。
同じテキストで左はFull、右はCuratedで画像出力したものです。
 FullとCuratedの違い
FullとCuratedの違いImage Resolution
画像サイズと出力枚数を設定します。
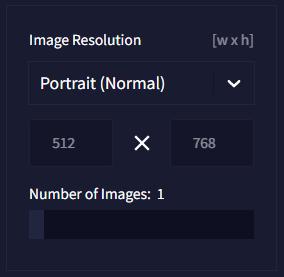 Image_Resolution
Image_Resolution画像サイズを選択するかカスタムで入力します。
テンプレートではNormal(普通)、Small(小)、Large(大)のそれぞれにPortrait(人物)、Landscape(風景)、Square(四角)が用意されています。
Number of Imagesでは生成する画像の枚数を1~4の範囲で設定します。
多く生成するほうがAnlasを消費します。
Module-Specific Settings
AIの判断に大きく関わり、出力画像のクオリティに影響する設定項目です。
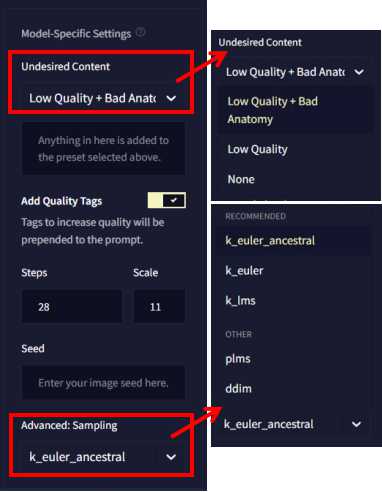 Module-Specific_Settings
Module-Specific_SettingsUndesired Content
デフォルトの「Low Quality + Bad Anatomy」のままでOKです。
低クオリティのもの、好ましくないものは除外するという設定です。
Add Quality Tags
デフォルトのチェックONのままでOKです。
テキストを入力するとき、タグを提案するかどうかを設定しています。
ONにしていると、学習済み(画像生成の精度の高い)タグを提案してくれます。
たとえば画像の例では「Japanese」と打とうとすると、複数のタグが提案されています。
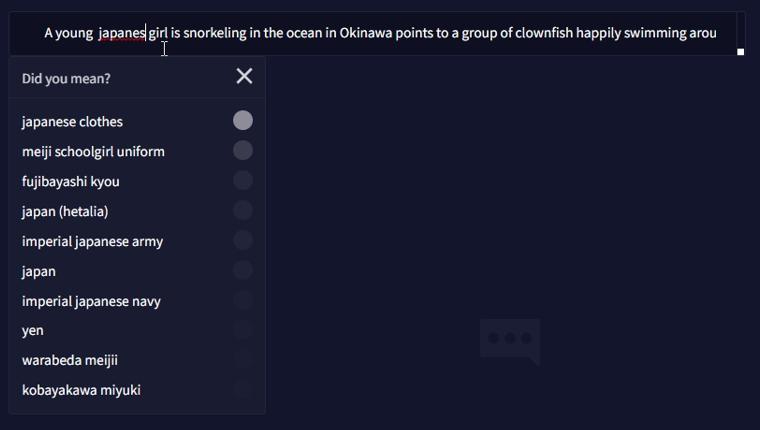 tag_suggested
tag_suggestedSteps
StepsとScaleはもっとも大きく画像生成のクオリティに関わるパラメータです。
 StepsとScale
StepsとScaleデフォルトのStepsは28が設定されています。最大値は50です。
StepsはAIが生成する画像を反復調整する回数を意味しており、Steps数を多くするほど解析の時間が長くなります。
Steps数を多くするほど画像のクオリティが上がるというわけではなく、多すぎる場合は逆効果になると解説されています。
次の画像は左が「デフォルト(Steps:28、Scale:11)」、右が「Steps:38、Scale:22」で出力したものです。
 StepsとScaleの違い
StepsとScaleの違いScale
Stepsと同じく画像生成のクオリティに関わるパラメータです。
デフォルトのScaleは11が設定されています。
ScaleはテキストをAIが解釈する余地を意味していて、値が小さいほどAIが自由に解釈して創造的な画像を生成します。
Scaleを上げるとAIが解釈する余地が少なくなり、より厳密にテキストを解釈します。
また、公式の英語ドキュメントでは、Scaleが低いほどより絵画的で幻想的になり、Scaleが高いほどより細かいディテールとシャープネスが得られるとあります。
いろいろと実験したところ、Stepsはある程度多くても問題なく、Scaleは大きすぎると線の強い画風になるようです。
AIに任せる余地を大きくするなら、Scaleは小さめ(11以下)に設定したほうが良さそうです。
Seed
とくに入力は不要です。
Seedは画像出力時に個々の画像に設定され、出力ファイルの末尾に付けられます。
たとえば「blond hair girl, smile, s-1709801714.png」のファイルだと末尾の「1709801714」がSeedです。
これはAI が個々の画像を計算するために使用した正確な方法を指定するもので、画像生成時にSeedを指定すると、同じ方向性(計算)で画像を生成します。
いまいち使い方が分かっていませんが、気に入った出力画像と同じ方向性でAIに画像を生成してほしい場合に使うようです。
Advanced:Sampling
デフォルトの「k_euler_ancestral」でOKです。というか、これを公式も推奨しています。
「異なるプロセスでサンプリングしているので、異なる結果を出力する」と説明にあります。
画像生成の知識がないならそのままにしておけ、とあるので、そのままにしておきましょう。
画像をインプットして生成する
画像をインプットして生成する場合、ほとんどはテキスト生成の場合と同じです。
もちろん、画像+テキストで生成できます。(画像だけでも半角スペースとかで生成できます)
画像をインプットする場合は「Uploaded Image Settings」のパラメータが追加されます。
「Strength」と「Noise」の2つが設定項目で、どちらも画像生成に大きく影響する重要なパラメータです。
また、Stepsは50で固定され、入力できなくなります。
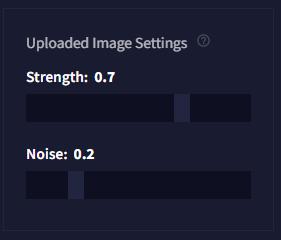 UploadImageSettings
UploadImageSettingsStrength
どれだけインプット画像を参考にするか(近づけるか)という強度を表します。
値が低いほどオリジナル画像に近く生成され、値が高いほどAIが解釈する自由度が増します。
デフォルトでは「0.7」に設定されています。
次の画像は左上の画像を入力として、テキストを「beautiful female teacher, brown curly hair, light smile, brown eyes,」として出力したものです。
StrengthとNoiseを極端に変化させて実験しましたが、かなり分かりやすく違いが出ていると思います。
 StrengthとNoiseの違い
StrengthとNoiseの違い「Strength:0」はほぼオリジナルと変わらないですね。
線画に着色とか、ラフを仕上げるとかに使うのは良さそうですが、他人の画像をインプットとしてこのレベルで生成するのはモラルハザードです。
「Noise:0.99」はあまり違いが出ていませんが、テキスト入力にが人物の設定のみで、背景の指定が無かったためです。
次のNoiseで説明します。
Noise
NoiseはAI が画像に新しい詳細を追加する度合いを示しています。
Noiseの値が大きいほど、AIが追加で詳細を追加します。
たとえば、背景のない画像を入力してテキストで背景を指定するなどで使います。
次の画像は画像を入力せずにテキストだけで出力したものと、画像入力ありでテキストに「beautiful female teacher, brown curly hair, light smile, brown eyes, classroom」と場所を指定して出力したものです。
背景が追加されているのが分かります。
 StrengthとNoiseの違い
StrengthとNoiseの違いNovelAIは使い方次第でいろいろなことができそうです。
画像インプットとテキストインプットを上手に組み合わせ、AIの判断の余地を残しつつ、いかに生成したいイメージを伝えるか、ですね。
AIに書かせるために入力するテキストを「呪文」と呼んだりしますが、NovelAIは呪文と呪文の解釈レベルをどうするかという焦点のようです。
NovelAIの始め方(登録方法・支払方法)はこちらでまとめています。

読書の習慣がある人は幸福度が高い、らしい。
2021年に読んだ本



2020年に読んだ本










-320x180.jpg)